Langchain : introduction

Today, we only hear about AI, and more specifically, Generative AI, since the emergence of ChatGPT. Everyone enjoys using it on the OpenAI website, typically to obtain information or for interactive assistance. This technology is also heavily used for creating dedicated assistants for very specific tasks. If you too want to integrate this kind of functionality or even develop a tool from scratch based on Generative AI, you'll find that there are several alternatives, and organizing them can be tricky.
In this new series of articles, I am creating a guided journey for building applications based on large language models using a popular framework called Langchain. We will see how this set of libraries simplifies the creation of applications around AI through diagrams and code examples.
While Python is the preferred language for AI, I've opted here for the JS variant of the library in order to easily integrate these features into a modern tech stack such as Next.js.
In this first article, I describe the main challenges you'll face when working with AI and introduce the basic concepts of Langchain.
Challenges
Limited Text Size
The prompts you may have used with ChatGPT support a limited number of tokens. In other words, the amount of text you feed into the AI cannot exceed a certain number of words. For instance, ChatGPT accepts around 3,800 words, and it's much less for other models. However, you may be looking to customize your AI with large volumes of input text which constitutes an initial obstacle for your application development.
Briefly, here's a quick reminder of what a token is: a token is a text unit identified by the AI within a text. Although one might think that a word is equivalent to a token, that's not the case. Some words are divided into multiple tokens if they contain a sequence of characters recognized by the AI based on its training set. The character sets most frequently seen in the texts it was trained on will be tokenized and thus recognized in words because the AI considers them as being significant for understanding the sentence. Feel free to try it yourself.
The commonly used rule of thumb to estimate the number of tokens in a sentence is that one token is equivalent to 3/4 of a word (in English).
Very General Training Data
Large Language Models (referred to as LLMs) have been trained on a huge amount of data and you can't verify its content or authenticity. If you want to build an application focused on a specific domain, how can you be sure that the selected AI contains all the relevant data for your business?
Although the models are somewhat documented, the limited information you have inevitably exposes you to inaccuracies in the tool's responses.
However, it is possible to provide reference information to a model to make it more relevant to your needs, as we'll see later.
The Complexity of Prompts
To be efficient, a prompt must contain a complete context that will help the tool respond as accurately as possible to the query. This involves defining roles, instructions, including things not to do/say, and providing examples. Besides, for your prompt to be usable by your customers, it will partially contain information that they provide and achieving a precise solution in all cases will not be easy.
Furthermore, the size of the prompt is a problem, as well as scaling it to address a growing number of customers.
Formatting Unstructured Data
The external data you that you may want to add to your model can be in various formats, such as PDF, Excel, or even proprietary ones. To make your model capable of using this data, you will need to convert it into the format expected by the model first. The question of storing this information will also be a point to address to easily make it exploitable in the future.
Pricing
OpenAI has become quite popular on social media with ChatGPT, but using it in an application (API calls) is not free. Billing is done per token and varies depending on the selected model (gpt 3.5, gpt 4, ...).

Although it may seem cheap, prices can quickly add up when dealing with large volumes of text.
Langchain
Langchain is a framework for developing applications based on LLMs with a set of components that can be assembled to build chains. Each component has a specific role in the chain and allows you to fine-tune the performance of the LLM for your application. The concept of chaining things is very representative of how the library works because each component is actually a link that plays its role and passes the result to its neighbor.
One of Langchain's major strengths is the availability of predefined chains that are suitable for the simplest types of applications in just a few lines of code, such as creating a chatbot or a summarization tool.
Another major advantage for me is the number of third-party API integrations that let you use various models or tools very easily.
Components
The official documentation is, of course, the reference point, and this article does not intend to replace it. Here are the main components of a chain and their roles.
| Component | Description |
|---|---|
| Model I/O | The minimal chain will always consist of input text (or prompt), an LLM, and output text (response). This component provides tools to format the prompt by integrating parameters, examples, etc. (PromptTemplate), to select from available models (LLM, ChatModel), and to extract useful information from the returned response (OutputParser). |
| Data connection | This set of tools is intended for customizing your model by injecting third-party data. You can load documents (DocumentLoader), break them into smaller chunks for LLMs (document transformers), convert them into a format understandable by LLMs (Embedding), store them (VectorStore), and finally query them for information retrieval (Retrievers). |
| Chains | Chaining multiple components (including other chains) is possible with this library. Ready-to-use chains are also available. |
| Memory | Memory typically serves to retain the conversation state so that each new message is not interpreted out of context. |
| Callbacks | As the name suggests, this component allows attaching intermediate logic in the execution of your chains. |
Typical Use Cases
With the concept of Runnable, all components are independent and can be chained or nested. However, it is not necessary to always use all of the components as illustrated below.
Basic Q&A

The simplest approach for using an LLM is to instantiate it and call it with a query to obtain a response. This solution is based entirely on the default training of the LLM.
import { OpenAI } from "langchain/llms/openai";
import * as dotenv from 'dotenv';
// Load your .env file containing your private api keys
dotenv.config();
// Create the LLM
const llm = new OpenAI({});
// Call the LLM
const res = await llm.call("Tell me a joke");
// Print the output
console.log(res);
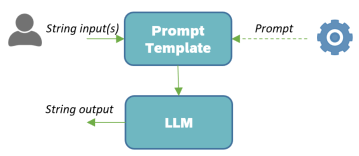
Chain with Advanced Prompt
When you want to add context to the prompt to achieve better results, the use of a PromptTemplate is helpful.
import { OpenAI } from "langchain/llms/openai";
import * as dotenv from 'dotenv';
// Load your .env file containing your private api keys
dotenv.config();
// Create parametric prompt
const promptTemplate = new PromptTemplate({
template: "Give me a {adjective1} and {adjective2} name for my watch manufacturing company",
inputVariables: ['adjective1', 'adjective2']
})
// Create the LLM
const llm = new OpenAI({ temperature : 1 });
// Create a chain
const chain = new LLMChain({
llm: llm,
prompt: promptTemplate
});
// Execute chain
const res = await chain.call({
adjective1: "friendly",
adjective2: "innovative"
});
// Print the output
console.log(res.text);
Please note that the LLM has been configured to be creative with the temperature parameter. 0 makes the LLM precise, while 1 makes it imaginative. Feel free to use intermediate values to gauge the creativity of your LLM.
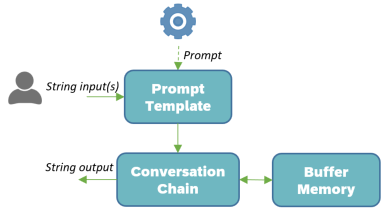
Chain with Memory
In the following example, we define a buffer for storing messages exchanged with the AI. Memories are primarily used for chatbot-type applications.
import { OpenAI } from 'langchain/llms/openai';
import { BufferMemory } from 'langchain/memory';
import { ConversationChain } from 'langchain/chains';
import * as dotenv from 'dotenv';
// Load .env
dotenv.config();
// Declare model
const model = new OpenAI({});
const memory = new BufferMemory();
const chain = new ConversationChain({
llm: model,
memory
});
const res1 = await chain.call({
input: "Hi I'm Jimmy"
});
const res2 = await chain.call({
input: "What is my name ?"
}); // outputs Jimmy thanks to memory
Indexes
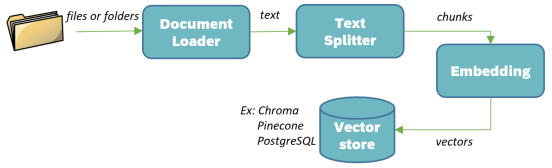
Information extraction from external documents is done through a pipeline that involves loading the text, breaking it down, and transforming it into vectors that are then stored in a database. This storage can be injected into a chain to enhance the quality of the response.
import { loadQARefineChain } from "langchain/chains";
import { OpenAI } from "langchain/llms/openai";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "langchain/embeddings/openai";
// Create the models and chain
const embeddings = new OpenAIEmbeddings();
const model = new OpenAI({ temperature: 0 });
const chain = loadQARefineChain(model);
// Load the documents and create the vector store
const loader = new TextLoader("./my_grandma_recpies.txt");
const docs = await loader.loadAndSplit();
// Store it in memory
const store = await MemoryVectorStore.fromDocuments(docs, embeddings);
// Select the relevant documents
const question = "What's the recipe of french crepes ?";
const relevantDocs = await store.similaritySearch(question);
// Call the chain
const res = await chain.call({
input_documents: relevantDocs,
question,
});
console.log(res);
The TextSplitter divides the large initial text (using \n, \n\n, and ) into smaller pieces to optimize searching with the similaritySearch call. These smaller chunks of text are then transformed into vectors (or Embeddings) relative to the selected model. This means that the number of dimensions in your vector will vary depending on the model you're working with. There are different vector comparison algorithms:
dot product: a scalar value representing the sum of the products of vector magnitudescosine similarity: the cosine of the angle between two vectors, calculated by dividing the dot product of the vectors by the product of their magnitudes.
The closer the result is to 1, the closer the vectors are. The number of vector dimensions plays a significant role in your model's performance. A higher number of dimensions leads to longer computations. So, while accuracy increases with dimension, performance decreases.
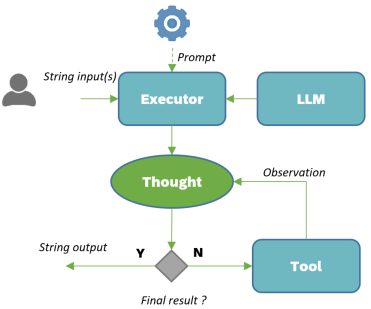
Agents
With agents, you enter the world of automation. You have the option to integrate tools that complement your LLM's capabilities. The most impressive aspect here is that the agent is controlled by an Executor, which will iteratively process the initial request until the final result is obtained. Thus, the request will be internally evaluated and broken down into a series of actions delegated to the LLM or one of the tools. The response will then be assessed, determining the necessary next steps for constructing the response.
import { OpenAI } from 'langchain/llms/openai';
import {SerpAPI} from 'langchain/tools';
import {Calculator} from 'langchain/tools/calculator';
import {initializeAgentExecutorWithOptions} from 'langchain/agents';
import * as dotenv from 'dotenv';
// Load .env
dotenv.config();
// Declare model
const model = new OpenAI({
temperature: 0
});
// Declare tools
const tools = [
// Google search api
new SerpAPI(process.env.SERPAPI_API_KEY, {
hl: 'en',
gl: 'us',
}),
new Calculator()
];
// Create agent
const executor = await initializeAgentExecutorWithOptions(tools, model, {
agentType: "zero-shot-react-description",
verbose: true, // debugging feature tracing all intermediate steps
});
// Execute agent
const res = await executor.call({
input: "prompt",
})
Conclusion
This first article provides a very schematic overview of the working concepts of Langchain. In the following articles, I will delve into specific cases that make the most of the many tools made available by this framework.